摩尔定律——多种解释(四川半导体微组装设备公司)
摩尔定律是戈登摩尔的观察结果,即计算机芯片中的晶体管数量每两年增加一倍。这条定律经常被许多人误解。
结合摩尔定律和登纳德扩展意味着,即使没有任何架构或微架构创新以及额外的处理器内核,只需在下一个节点中重新调整芯片,CPU 就可以在总功耗相同的情况下以 50% 的面积实现 40% 的性能提升。
第一个拐点——晶体管性能下降

图 1 :晶体管性能下降的第一个拐点
到 2012 年,GPU 等特定领域加速器开始获得更大的发展动力。在网络方面,通用网络处理器让位于固定管道数据包处理架构,该架构对大部分 L2/L3 处理进行硬编码。此外,为了减少访问外部存储器所涉及的延迟和功耗,一些网络公司为其高端交换机采用了 VOQ 架构。
CMOS > FinFET > GAA
随着CMOS器件性能的下降,业界在2012-2015年左右迅速采用FinFET晶体管技术。英特尔于 2011 年通过其 22 纳米工艺节点将 FinFET 引入主流半导体制造,但没有取得太大成功。台积电在 16nm 工艺节点推出 FinFET。 (四川成都半导体微组装设备厂家)
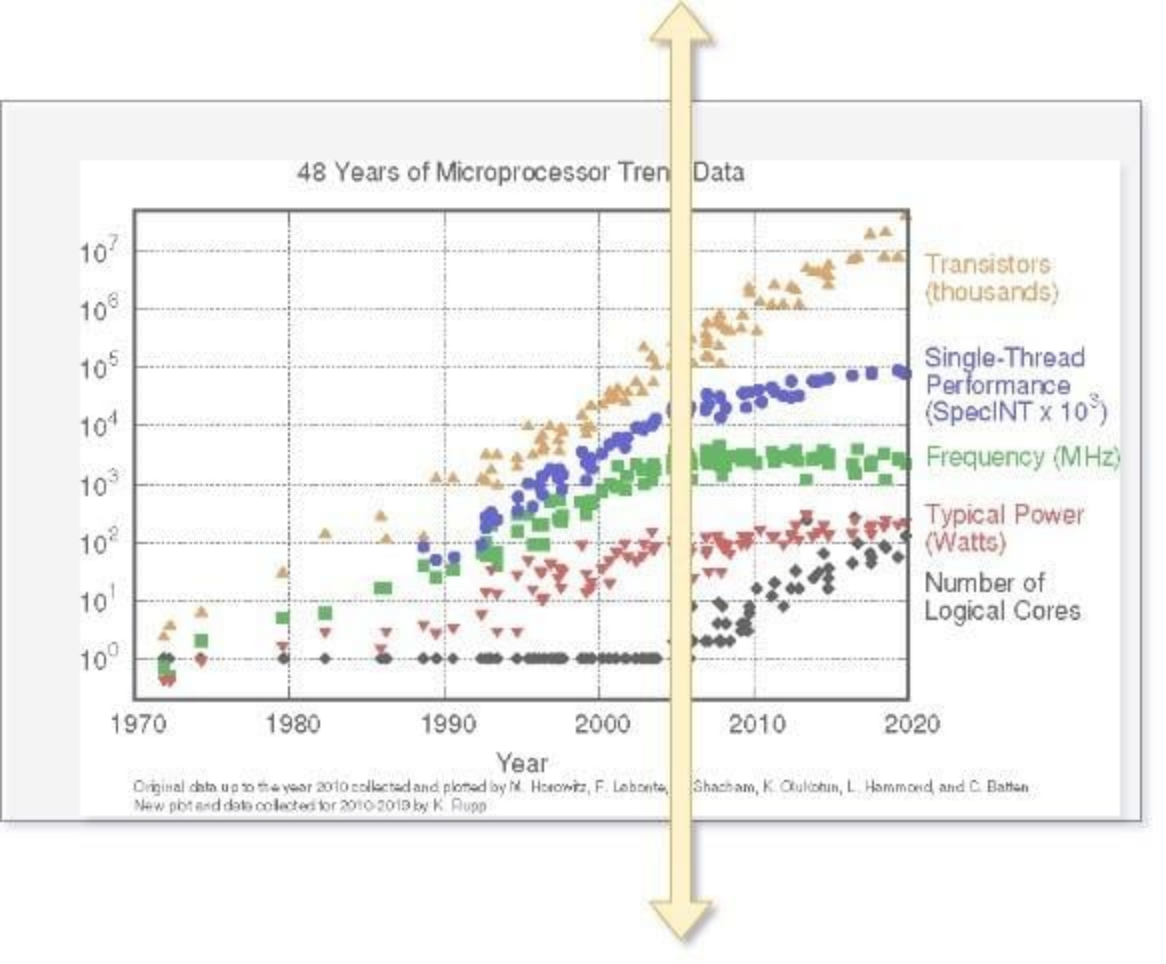
图 2 :晶体管技术。来源:三星
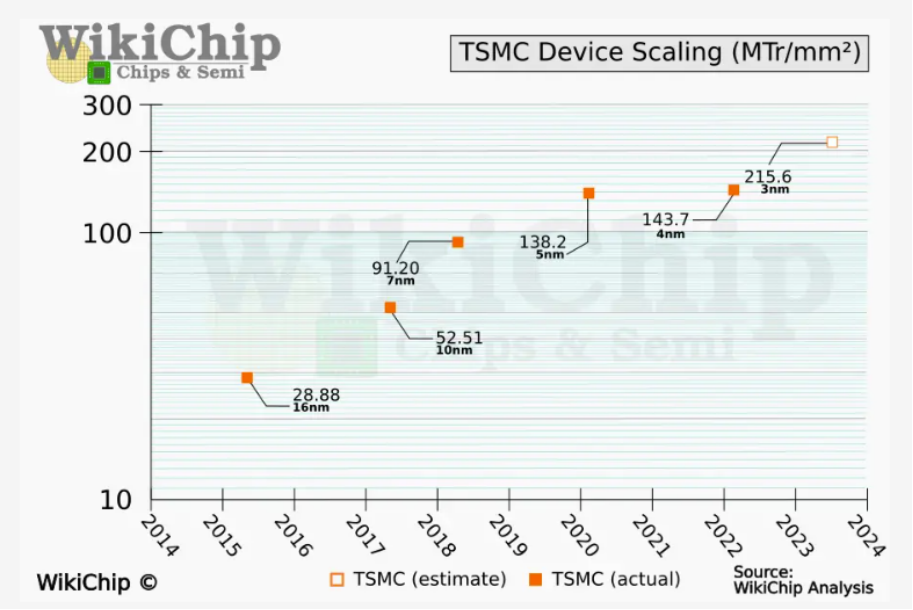
图 3:晶体管密度随着每个工艺节点不断增加。高性能晶体管的密度通常比上面所示的通用(高密度)晶体管低。来源:维基芯片
第二个拐点——2.5D融合
用作 GPU/CPU 和网络设备外部存储器的 DRAM 使用与 ASIC 中的晶体管所使用的不同的处理节点。很难同时扩展 DRAM 的性能和密度,同时保持较低的成本和功耗。由于 CPU 供应商对容量的需求增加,DRAM 供应商以容量而非性能为代价。由板上 PCB 走线主导的 DRAM 延迟也没有改善。DRAM 与逻辑性能之间不断扩大的差距通常被称为“内存墙”。
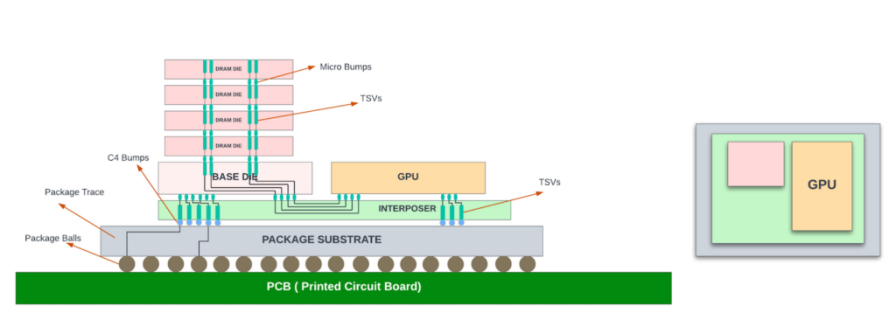
图 4:HBM 插图。模具高度未按比例绘制。
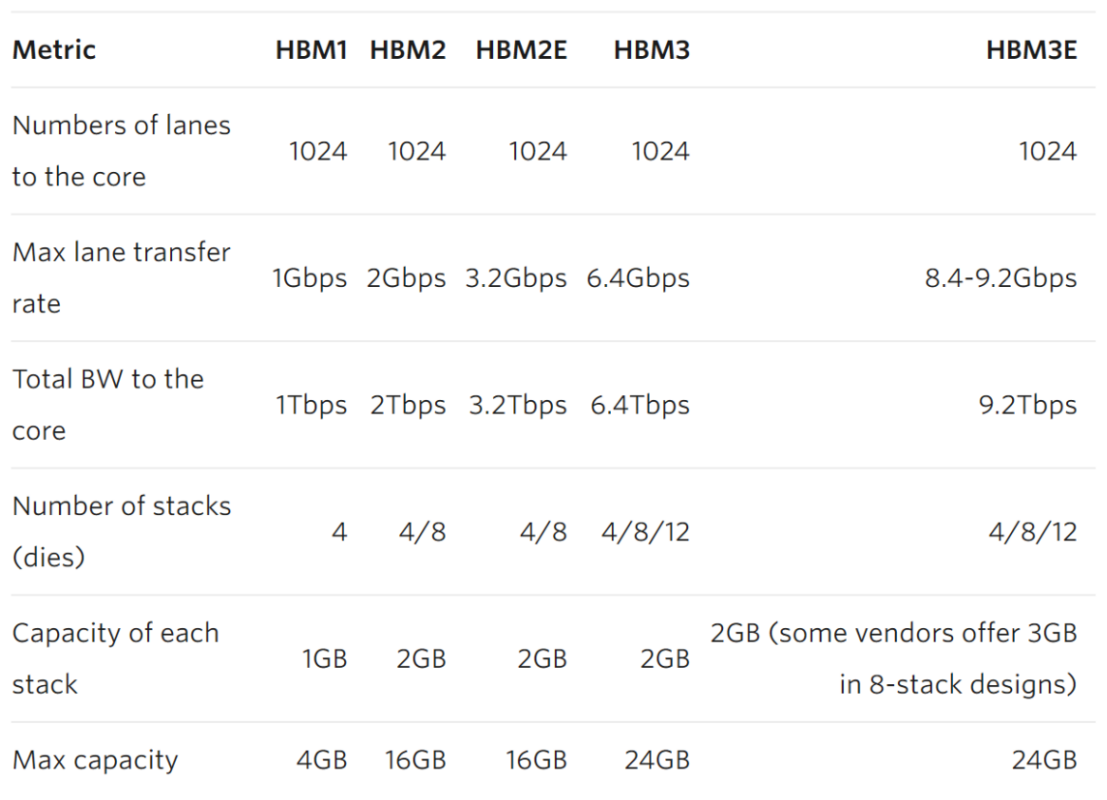
多年来 HBM 性能和容量的增长。
请注意,Intel、AMD 和 Apple 的桌面 CPU 继续使用 DDR 内存变体,因为 HBM 部件和 2.5D 封装价格昂贵,而且成本并不能证明带宽增益的合理性。此外,主板上的 DDR 内存 (DIMM) 允许用户根据需要升级或更换内存,并以低得多的价格提供比 HBM 设备更高的内存容量。如果 CPU 使用封装 HBM 作为其主内存,则这种用户驱动的可升级性将会丢失。PC 生态系统(尤其是基于 x86 的)是建立在数十年的遗留基础设施之上的。将 CPU 过渡到新的内存标准将广泛影响 PC 市场,包括主板、兼容性、软件等。
多芯片模块 (MCM) 时代
MCM 背后的理念
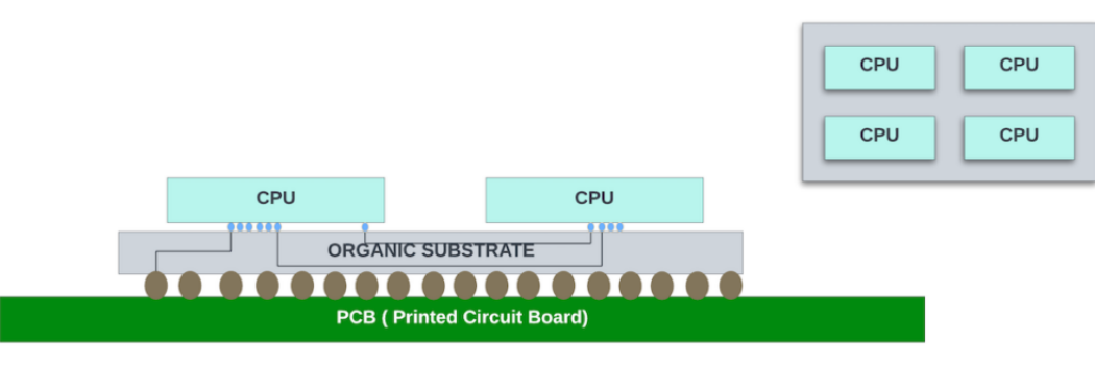
图 5:具有四个 CPU 芯片的 MCM。
高速 SerDes 用作小芯片之间通信的物理介质。AMD 开发了专有的 Infinity Fabric 协议。该协议用于 CPU 内的处理内核、封装中的 CPU 小芯片以及两个不同插槽上的 MCM 之间的通信。在所有内核到内核通信中使用相同的协议使得小芯片架构更容易扩展到四个 CPU 之外。
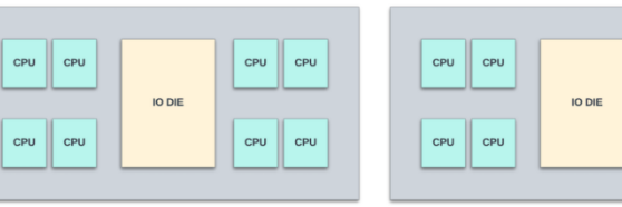
图 6:14 纳米工艺中具有 IO 芯片(带有 DDR 控制器、PCIE 接口等)的 Zen2 MCM 和 7 纳米工艺节点中的 CPU 内核的图示。
二十多年来,英特尔一直在为其处理器核心使用有机基板的 MCM 进行修补,但并没有在所有 x86 系列中一致使用它们,因为他们优先考虑功耗/性能而不是成本。与将所有这些核心封装在单片芯片中相比,CPU 之间具有较长走线的 MCM 显著增加了核心间通信的延迟。
英特尔专注于先进封装
英特尔专注于开发先进封装,以实现高密度小芯片互连,同时降低延迟和功耗。在其开发的众多技术中,“Foveros”和嵌入式多芯片互连桥(EMIB)最为突出。
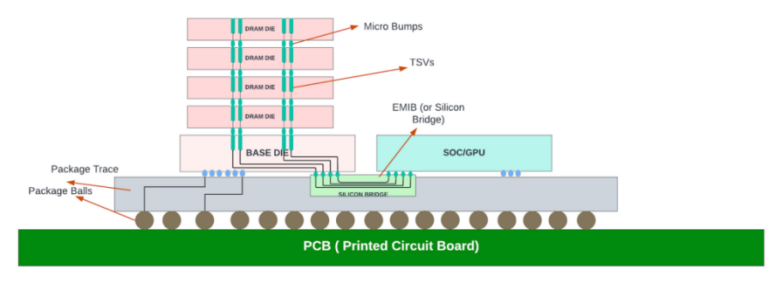
图 7:用于 HBM 和核心连接的 EMIB。
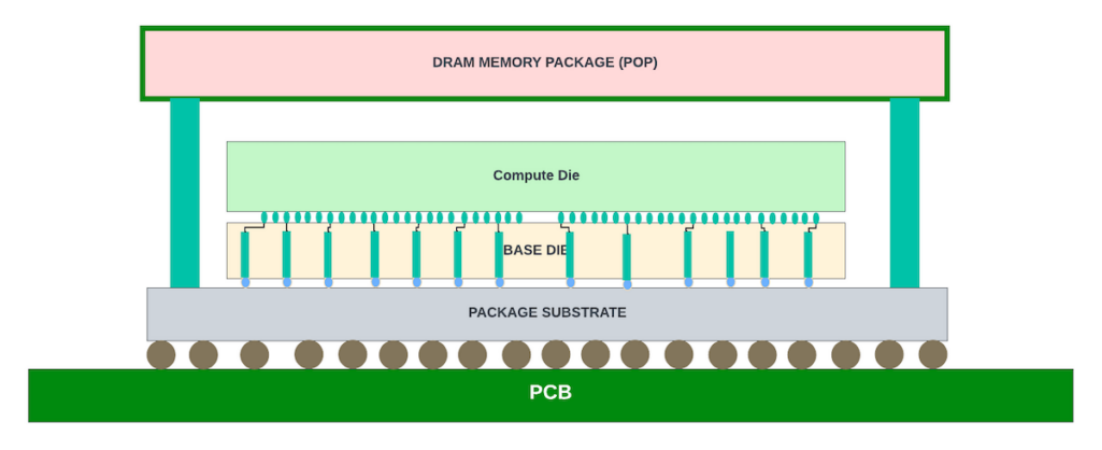
图 8:基础芯片、计算芯片和叠层封装 (POP) DRAM 之间的 3D 堆叠(Foveros 插图)。
Apple 最近发布了最新的桌面 CPU 芯片 (M1 ultra),该芯片使用大型硅中介层来背靠背连接大型 M1 Max 芯片(每个芯片约 500 平方毫米)。它使用专有的封装技术通过硅中介层在芯片之间连接超过 10,000 个信号,在芯片之间提供约 20Tbps 的带宽。
先进的 3D 封装
尽管 SRAM 随着每个工艺节点的缩小而缩小,但其缩放比例无法与晶体管缩放相比,并且与逻辑门相比,它们在密度和性能改进方面开始落后。跨多个内核共享的统一大型 L3 缓存有助于抵消 SRAM 扩展问题,并允许在单片芯片中更多地集成内核。同样,在网络方面,统一的数据包缓冲区和数据结构在多个 PFE 之间共享,并且数据包缓冲区进一步减少,有利于更好的端到端拥塞机制。
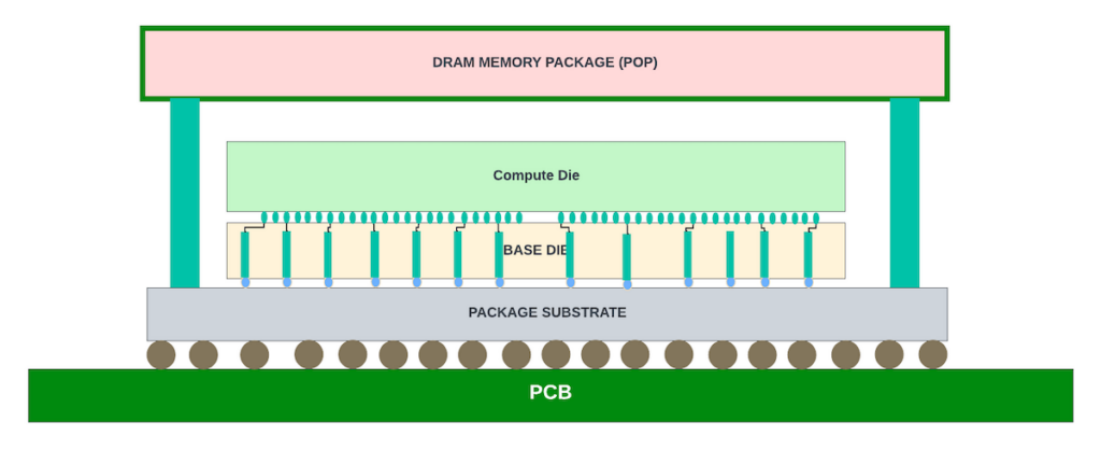
图 9:TSMC 的 SRAM 缩放在 3nm 工艺节点停止。与 5nm 相比,密度没有提高。来源:维基芯片
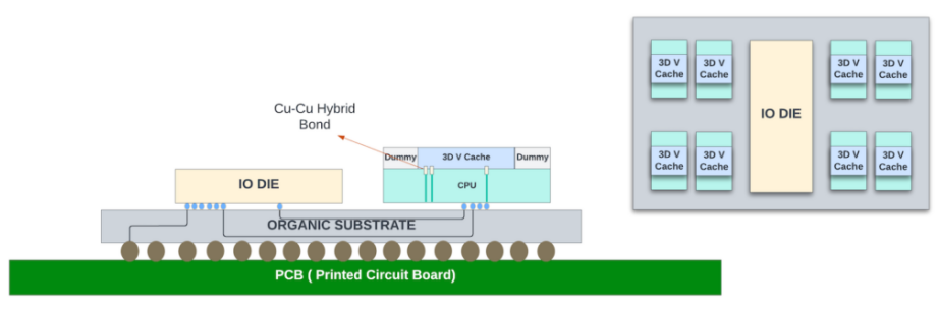
图 10:垂直方向堆叠的小芯片之间的 Cu-Cu 混合键合。
英特尔的 Fevoros Direct 与台积电的 SoIC 非常相似。它在芯片之间使用铜-铜键合,允许互连之间的间距更细(<10um)。
先进封装:结合 3D 和 2.5D 堆叠
具有多个 CPU/GPU 和 HBM 接口的数据中心服务器可以受益于垂直方向的 3D 堆叠和先进的 2.5D 堆叠,以实现硅中介层/EMIB 上小芯片和 HBM 之间的互连。
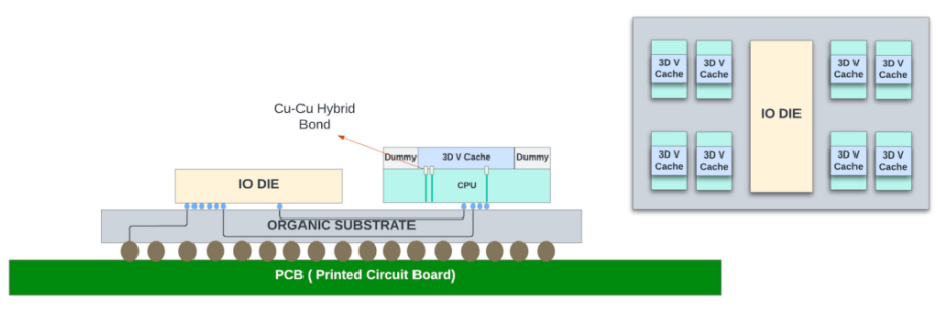
图 11:采用 HBM 和小芯片 3D 堆叠的先进封装。尺寸不按比例。
英特尔也有类似的数据中心级服务器芯片,将 GPU/CPU/HBM 集成到其 Falcon Shores 系列服务器芯片中。Falcon Shores 系列可能使用英特尔的 EMIB 进行水平堆叠和 Foveros Direct(用于垂直连接)。
先进封装——集成扇出晶圆工艺
Tesla 和 TSMC 已采用晶圆级集成扇出 (INFO) 晶圆上系统 (SOW) 封装。在此 INFO SOW 工艺中,从晶圆上切割出各个芯片。然后,将已知良好的芯片精确地重新定位在载体晶圆或面板上,并在每个芯片周围留出用于扇出接口信号的空间。
然后通过模制来重构载体晶圆。重新分布层(RDL)形成在整个模制区域的顶部。焊球放置在 RDL 的顶部。这消除了对封装基板和 PCB 的需求,并使芯片之间的互连变得高效。
图 12 :晶圆 (SOW) 技术上的集成扇出 (INFO) 系统。
另一个营地
AMD 和英特尔全力开发基于小芯片的桌面/服务器 CPU 和 GPU 架构,而英伟达则继续开发大型单片 GPU,除了 HBM 的 2.5D 集成。这是有充分理由的。这些小芯片增加了额外的延迟,这会影响消费者游戏 GPU 的性能,而英伟达不愿意妥协。
此外,即使他们继续在 2nm 工艺节点中构建光罩大小的芯片,小芯片架构也确实可以帮助他们。例如,他们可以通过使用 NVLink 协议的芯片间互连来连接多个标线大小的芯片,并创建具有多个 GPU 的 ASIC 封装。这将减少 8-GPU 服务器中 ASIC 的数量,并有助于整体降低功耗和延迟。看看英伟达会为其 2nm GPU 采用哪种封装技术和方法将会很有趣。
网络芯片
与英伟达一样,网络芯片供应商继续专注于构建单片芯片有几个原因。
随着中介层和互连技术的成熟,瞻博网络通过 Express 5 芯片 (2022) 实现了信心的飞跃,并尝试在 2.5D 封装中实现小芯片的异构集成。
Express 5硅
两个基本小芯片被用作构建块,以支持八种不同的 ASIC 封装。
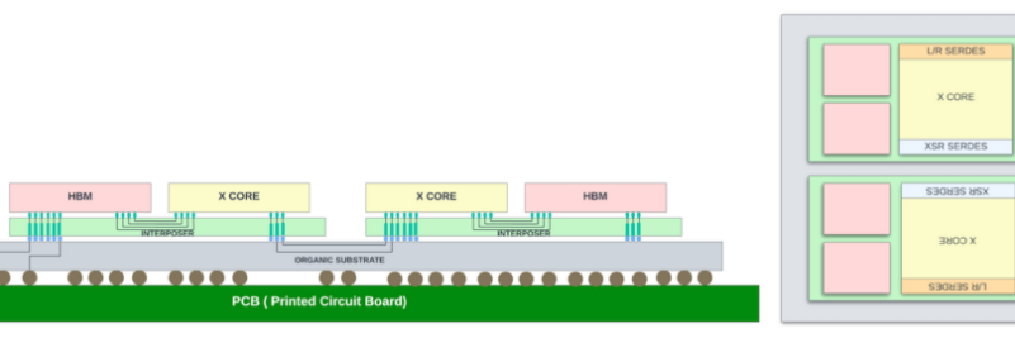
图 13 :Express 5 芯片中使用的具有硅中介层 (S) 封装的 CoWoS。28.8Tbps 独立交换机 ASIC。
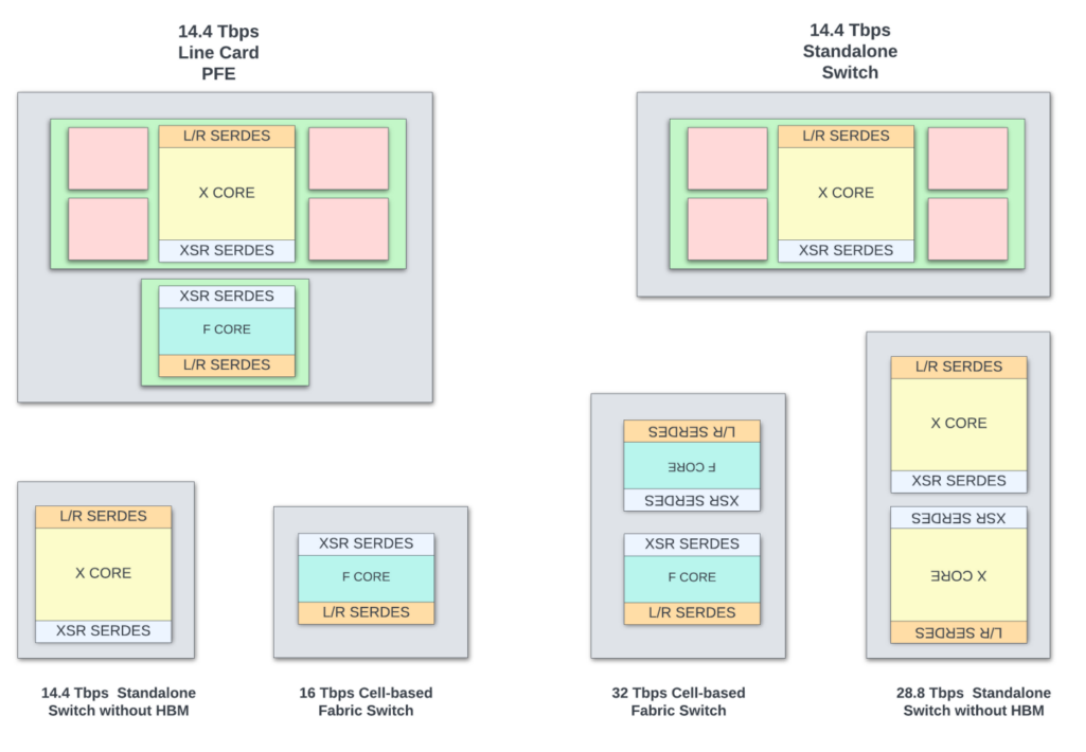
图 14:两个小芯片和许多封装。
总之,选择小芯片方法是在成本/功耗/性能和上市时间要求之间进行仔细权衡。ASIC 的成本除了总功能面积和小芯片的尺寸之外,还很大程度上取决于产量和代工合作伙伴,因此没有一种方法适合所有高端网络芯片供应商。
高端网络芯片——未来趋势
除瞻博网络外,没有其他高端网络芯片供应商在其交换机中使用小芯片方法。其中一些 TOR 交换机已经接近标线极限,具有 51.6Tbps 的交换容量。为了在封装内达到 > 100Tbps 的交换容量,在没有 SRAM 扩展和 SerDes 扩展较低的情况下,它们很可能必须依赖小芯片架构。
将全部或部分片上数据包缓冲移至与主 PFE 芯片 3D 堆叠的内存小芯片也有助于增加高端交换机的延迟带宽缓冲和路由规模。
Chiplet — 优点/缺点回顾
总体而言,过渡到基于芯片组的架构应该有助于所有高端 ASIC,其中总功能硅的面积远高于掩模版尺寸。小芯片方法在很多方面都有帮助。
尽管业界正在大力解决热和机械挑战,但小芯片架构确实为许多应用提供了成本/功耗/性能之间的更好平衡。
芯片间互连的标准化
通用小芯片互连规范使来自多个供应商和跨不同工艺节点的小芯片能够在封装中共存。它还在供应商之间创造良性竞争并促进创新。
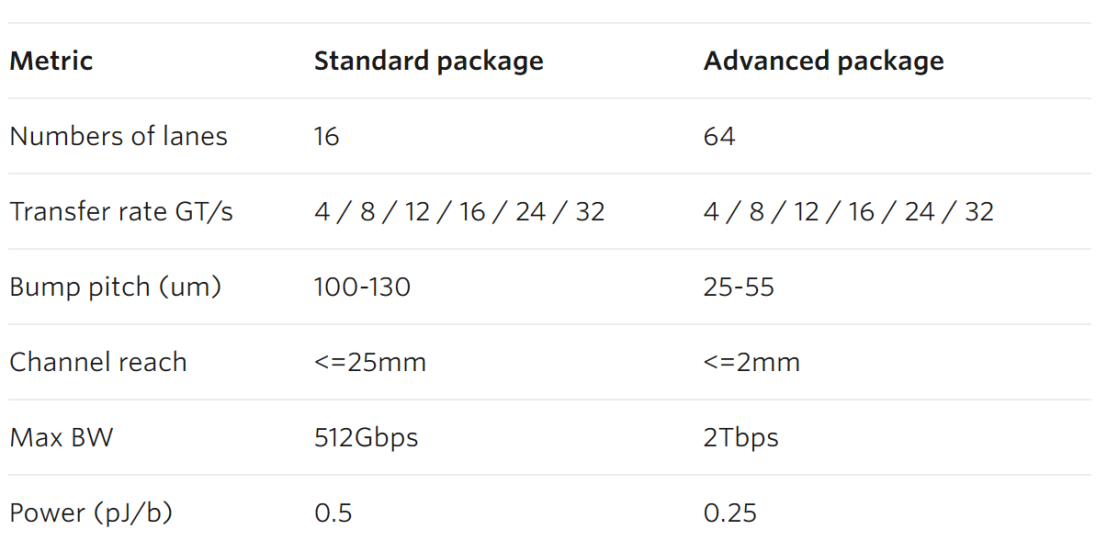
表 2:UCIE 中的指标示例。
未来趋势
对于所有希望在封装内集成比光罩大小芯片所能提供的更高吞吐量的高端 ASIC,小芯片将继续存在。封装技术、高速/高密度小芯片互连以及用于冷却封装内这些小芯片的热管理方面的持续创新对于保持这一势头至关重要。
更多的四川半导体微组装设备资讯请联系:18980821008(张生)19382102018(冯小姐)
四川省微电瑞芯科技有限公司http://www.wdrx-semi.com/




